|
|
|
Metin Madenciliği Ile Metin Sınıflandırma - 1 |
|
| Gönderiliyor lütfen bekleyin... |
|
|
Bu makalemizde Metin Madenciliğinin temellerinden (Text Mining) bahsedilecek,ileriki makalelerde de metin madenciliğinde kullanılan algoritmalar ile örnek uygulamalar yapılacak ve çok sayıda haber metninin yüksek bir doğruluk oranı ile nasıl otomatik olarak sınıflandırılabileceğini yapacağımız program ile göreceğiz.Öncelikle metin madenciliği ile ilgili genel bilgiler ile başlayalım.Yazı dizimizin sonunda internetten alınan rastgele haber metinlerini programa sokarak en uygun kategoriye atayacağız.Projemizde kullanacağımız matematiksel algoritmaları mümkün olduğunca anlaşılabilir olması için ayrıntılı açıklamaya çalışacağım.
Günümüzde veritabanlarında,internet ve intranetlerde çok büyük miktarda bilgi depolanır.Bu bilgi dökümanlarda veya metin dökümanlarında tutulmaktadır.Bu bilgilerden önemli bilgiler çıkartmak,keşfedilmemiş desenleri bulmak buradaki esas problemimizdir.Bu problem eskiden beri vardır.
Geleneksel olarak problem, Dewey ondalık sınıflandırma sistemi ile veya karakteristik anahtar kelimeler verme yöntemi ile dökümanları sınıflandırarak ve onlara böylece erişerek çözülür.Günümüzde bir çok şirket veritabanlarında,internet ve intranetlerde bir çok sınıflandırılmamış döküman bulunmaktadır.İlk olarak bazı terimlerin tanımlaması yapılmalıdır.
Metin Süzme: Dökümanların dinamik bir metin akımından seçilerek, bu dökümanlarda bilgi arama işlemidir.
Metin Madenciliği: Özel amaçlar için,metinden bazı bilgiler çıkarmak adına metinin analiz edilme işlemidir.
Metin Kategorizasyonu: Büyük bir dökümanlar kümesinden benzer dökümanları sınıflandırma işlemidir.
Tüm bu terimler, birbirleriyle örtüşmektedirler.Metin madenciliği (döküman bilgisi madenciliği,metin verisi madenciliği veya metinsel veritabanlarından bilgi çıkarımı olarak da bilinir),ilginç ve önemsiz olmayan örüntüleri veya bilgiyi çıkarma amacı için ,biçimsiz ve sayıca çok döküman analiz etme teknolojisidir.Çözülmesi gereken tipik problemler şunlardır: dil belirleme, terim seçimi/ çıkarma, kümeleme, doğal dil işleme, özetleme, kategorizasyon, araştırma, indeksleme ve canlandırmadır.
Dökümanların otomatik olarak sınıflandırılabilmesi için vektörel olarak ifade edilmesi,ve bu şekilde çeşitli algoritmalar kullanılması gereklidir.Bunun için vektör uzay modelinden kısaca bahsedelim
VEKTÖR UZAY MODELİ
Vektör uzay modeli bilgi çıkarımı,bilgi filtreleme,indeksleme gibi alanlarda kullanılan cebirsel bir modeldir.Doğal dil belgelerinin çok boyutlu uzayda özel bir anlamını simgelemektedir.
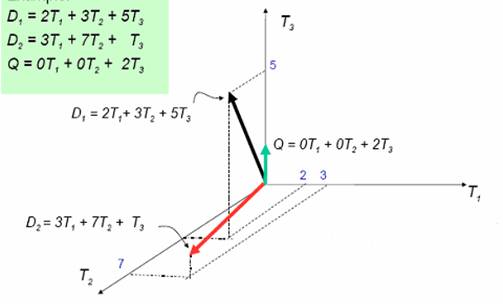
Dökümanlar şekilde götüldüğü gibi kelimelerin vektörleri olarak ifade edilirler.T’ler aslında kelimeleri ifade etmektedirler.
Anahtar kelime araması yapılan dökümanların ilişki düzeyleri, döküman benzerlik teorisindeki varsayımlar kullanılarak, yani her bir döküman vektörü ile orijinal sorgu vektörü arasındaki açıların sapmalarını karşılaştırarak, hesaplanabilir.
Vektörler arasındaki gerçek açıların hesaplanması yerine, vektörler arasındaki açının cosinüsü hesaplanır ve karşılaştırılır.(KNN Algoritması)
Temel Prensip
Metin sınıflandırma işleminin temel adımı sınıflandırmak istediğimiz dökümanı ve eğitim dökümanlarımızı vektörel olarak uzayda ifade edebilmektir.Bir çok metin sınıflandırma algoritması bu prensibe dayanır. Bunun için uzay eksenlerini belirlemeliyiz. Uzayımızın eksenlerini aslında bizim kategori belirttiğini düşündüğümüz kelimeler oluşturacaktır. Bu kelimeler de sözlükte, yani kelimeler tablosunda tutulmuştur.Bu tablonun nasıl ve hangi kurallara göre oluşturulacağı ilerleyen makalelerde anlatılacaktır.
Dökümanlarımızı vektör olarak temsil edebilmek için metnin içerisinde geçen kelimelerin bir takım işlemlere sokulması gereklidir(Pre-Processing). Bu işlemin sonucunda vektörlerimiz oluşacaktır.
Sistemimizin verilen metinden kategorileri otomatik olarak bulabilmesi için eğitilmesi gereklidir.Bunun için kategori belirten makaleler sistemimizi eğitmek için kullanılmıştır.Bu makaleler ile arka planda sözlüğümüzün boyutu ile sınırlandırılmış vektorler oluşturulup, kategorisi bulunması istenen dökümanın vektörü ile çeşitli algoritmalarla(KNN-Naive Bayes) karşılaştırılarak sınıflandırılmak istenen döküman ilgili kategoriye atanacaktır.
Ticari ürünler
http://www.clearforest.com/
http://www.trl.ibm.com/projects/textmining/takmi/takmi_e.htm
http://www.megaputer.com/
Metin inceleme
http://www.textanalysis.info/
Makalemizin 2.bölümünde görüşmek üzere.Herkese iyi çalışmalar.
İsmail Ferhat Pilavcılar
[email protected]
Makale:
Metin Madenciliği Ile Metin Sınıflandırma - 1 Yazılım Mühendisliği İsmail Pilavcılar
|
|
|
|
|
-
-
Eklenen Son 10
-
Bu Konuda Geçmiş 10
Bu Konuda Yazılmış Yazılmış 10 Makale Yükleniyor
Son Eklenen 10 Makale Yükleniyor
Bu Konuda Yazılmış Geçmiş Makaleler Yükleniyor
|
|
|