|
|
|
Hashing Fonksiyonları, Hash Tablosu ve Collision |
|
| Gönderiliyor lütfen bekleyin... |
|
|
Bu yazımızda yorumylayıcı (interpreter) tasarımında, derleleyicilerin bir
bölmünde, database uygulamarında, şifreleme yöntemleri geliştirmede md5,
sha1) yoğun olarak kullanılan hashing yöntemini inceleyek ve basit bir
uygulama geliştireceğiz. Genel anlamda tanımlayacak olursak; Hashing,
elimizdeki veriyi kullanarak o veriden elden geldiği kadar benzersiz bir
tamsayı elde etme işlemidir. Bu elde edilen tamsayı, dizi şeklinde
tutulan verilerin indisi gibi kullanılarak verilere tek seferde erişmemizi
sağlar. Bu daha önceden incelediğimiz arama yöntemlerine nazaran çok daha hızlı
sonuç verecektir. Hasing konusunu alt başlıklara ayıracak olursak;
-
Hashing Fonksiyonu
-
Hash Tablosu
-
Çatışma (collision)
Hashing Fonksiyonu
Bu fonksiyonun görevi kendisine verilen bir değerden
(value), benzersiz bir tamsayı (key) üretmesidir. Fakat uygulama alanında
herzaman benzersiz bir sayı üretecek uygun fonksiyonu bulmak çok zor hatta bazı
durumlarda imkansızdır. Eğer farklı iki değerden aynı sayı üretilirse bu duruma
çatışma denir(bu konuyu daha sonra inceleyeceğiz). Bir hashing fonksiyonundan
beklenenler :
-
Herhangi bir uzunlukda değer alabilmelidir.
-
Çıktı olarak belirlenen uzunlukta anahtar
(key) üretebilmelidir.
-
Tek yönlü olmalıdır. Fonksiyon tarafından üretilen
anahtardan fonksiyona verilen değer elde edilmemelidir.
-
Çatışmalara olanak vermemelidir.
Bizim uygulamamızda kullanacağımız hashing fonksiyonu
aşağıdaki gibidir :
#define MAX_ROW 16
int RSHash(char *str, int len)
{
int b = 378551;
int a = 63689;
int hash = 0;
int i = 0;
for (i = 0; i < len; str++, i++)
{
hash = hash * a + (*str);
a = a * b;
}
return (hash & 2147483647) % MAX_ROW;
} |
Fonksiyonda dikkat edeceğimiz nokta son aşamada
MAX_ROW ile mod işlemidir. MAX_ROW hash tablosunda kaç elemanı
saklayacağımızı belirtiyor. Bu mod alma işlemi ile elde edeceğimiz
benzersiz sayının tablomuzun sınırları içerisinde olmasını sağlıyoruz.
Hashing fonksiyonlarının interenet üzerindeki bazı uygulama alanlarını
inceleyebilirsiniz.
RFC
1321 (MD5 Message-Digest Algorithm, April 1992)
RFC
1828 (IP Authentication using Keyed MD5, August 1995)
RFC
2069 (An Extension to HTTP: Digest Access Authentication, January 1997)
RFC
2537 (RSA/MD5 KEYs and SIGs in the Domain Name System (DNS), March
1999)
RFC
2104 (HMAC: Keyed-Hashing for Message Authentication, February 1997)
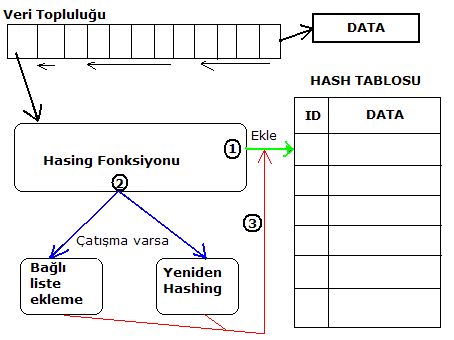
Hash Tablosu
Verinin ve hasing fonksiyonuyla elde edilen
değerlerin birlikte tutulduğu veri yapısıdır. Şimdi hem uygulamamızı
geliştirmeye devam edelim hem de hash tablosunu implemente edelim. Uygulamamız
birşekilde(mesela bir dosyadan okunarak) elde edilmiş kelimeleri hash
tablosuna yerleştirsin. Tablodaki her bir kaydı aşağıdaki yapı temsil etsin :
#define NAME_LENGTH 20
typedef struct _Row{
int index;
char name[NAME_LENGTH];
struct _Row *pNext;
}Row; |
index : Hashing fonksiyonu tarafından
üretilen değeri saklar.
name : Hashing fonksiyonuna verilen veriyi saklar.
pNext : Eğer farklı veriler için hashing fonksiyonu aynı değer
üretirse (çatışma olursa) aynı satırdaki diğer kaydı gösteren göstericiyi
temsil eder.
Tablomuz ise bu yapı türünden birçok kayıttan oluşacağından tablomuzu temsil
edecek yapı da aşağıdaki gibi tasarlayalım ve bu yapı türünden bir global
değişken tanımlayalım :
typedef struct _Table {
Row rows[MAX_ROW];
}Table;
Table table; |
 Tabiki tablomuzu kullanıma hazırlamamız gerekecektir.
Bunu yapacak fonksiyonumuz aşağıdaki gibi olacaktır:
Tabiki tablomuzu kullanıma hazırlamamız gerekecektir.
Bunu yapacak fonksiyonumuz aşağıdaki gibi olacaktır:
void initialize_Table()
{
int i;
for (i = 0; i < MAX_ROW; ++i)
{
table.rows[i].index = -1;
sprintf(table.rows[i].name, "%s", "$$BOS$$");
table.rows[i].pNext = NULL;
}
}
|
Çatışma (collision)
Farklı iki veriye karşılık hashing
fonksiyonu aynı değeri ürettiği duruma çatışma denir. Örneğin fonksiyonundan
"hastane" ve "pilav" verilerinden değer üretmesini istediğimizde aynı değeri
(örneğin 126435465699) üretebilir. Bu durumda çözüm olarak (collision
resolution) iki temel yaklaşımdan biri uygulanabilir.
-
Açık Adresleme (Open Addressing) :
Eğer hashing fonksiyonu tabloda daha önceden kullanılan bir indis değeri
üretirse, başka bir hashing fonksiyonu ile bir sonraki boş kaydın indis değeri
üretmesi sağlanır. Bu işlem boş indis bulunana kadar devam eder. Örneğin H(x) +
1; ile bu işlem sağlanabilir.
-
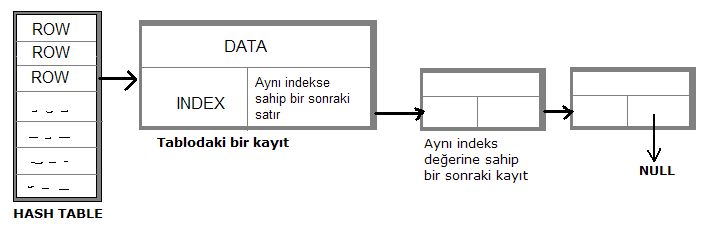
Bağlı Liste Kullanarak (Linking) :
Yukardaki şekildende görüldüğü gibi aynı indise sahip kayıtlar bağlı liste
kullanarak birbiri ile ilişkilendirilir. Hashing fonksiyonu kullanarak indis
elde edildiğinde bu bağlı liste üzerinde dolaşılarak kayıtlara ulaşılır.
Tabiki
bu yöntemlerin kendilerine göre avantajları ve dezavantajları vardır. Bağlı
liste kullanımında çoklu çatışamlar sınırsız olabildiği gibi açık adreslemede
yeniden hashing işlemi çok daha hızlı gerçekleşebilmektedir. Çatışma konusu
hashing fonksiyonlarının tasarlanması sırasında en çok üzerinde uğraşılan bir
konudur. Bazı durumlarda bu sorunun asla giderilemeyeceğini gözönünde
bulundurmak gerekir. Şimdi uygulamamızı anlattıklarımız doğrultusunda
geliştirmeya devam edelim. Tablomuzun yapısını oluşturduk. Şimdi tablomuza
kayıt ekleme işlemini gerçekleştirecek fonksiyonu yazalım :
void add_Row(char *str)
{
int hash_index;
Row *row;
hash_index = RSHash(str, strlen(str));
//Hasing fonksiyonu ile benzersiz bir değer üretiyoruz
if (table.rows[hash_index].index == -1 || (strcmp(table.rows[hash_index].name, str) == 0))
{ //kayıt ekle varsa güncelle
table.rows[hash_index].index = hash_index;
sprintf(table.rows[hash_index].name, "%s", str);
return;
}
row = (Row *)malloc(sizeof(Row));
//Aksi durumda bir kayıt oluştur
if (!row) {
puts("yeterli bellek yok!");
exit(0);
}
row->index = hash_index;
sprintf(row->name, "%s", str);
collision(row, &table.rows[hash_index]);
//ve çakışma listesine ekle
} |
Fonksiyonun ilk adımında veriden hashing fonksiyonu ile üretilen
benzersiz değer elde ediliyor. Daha önce tablomuzu ilk kullanıma hazırlarken
ilgili kaydın boş olduğunu belirtmek için index değerine -1 atamıştık.
Foksiyonda sonraki adımda, hash fonksiyonu ile elde ettiğimiz değerin hash
tablosundaki aynı indisli kaynına bakıyoruz. Eğer bu kaydın index değeri -1 ise
kayıt daha önce kullanılmamış demektir. Eğer index değeri -1 değilse bu defa o
kaydın verisine bakıyoruz. Elimizdeki veri ile o kayıttaki veri aynı ise
güncelleme işlemi gerçekleşiyor. Peki hem kaydın index -1 değilse hem de
veriler farklı ise o zaman ne yapacağız. İşte bu duruma daha önceden de
bahsettiğimiz gibi çatışma deniyor. Bu durumda örneğimizde hash tablosuna bağlı
liste kullanarak ekleme yapacağız. Bu işlemi ise collision isimli fonksyonumuz
gerçekleştiriyor. Fonksiyon eklenecek kayıt ile hash tablosunda hangi kaydın
sonuna eklenceğini belirten iki parametre almaktadır. Fonksiyonumuz
aşağıdaki gibidir :
void collision(Row *row, Row *startRow)
{
Row *old;
old = startRow;
while(startRow){
// Bağlı listenin sonu bulunuyor
old = startRow;
startRow = startRow->pNext;
}
old->pNext = row; // Son
elemana ilgili kayıt ekleniyor
row->pNext = NULL; //
bağlı listeninsonubelirleniyor
} |
 Bu aşamada hash tablomuzu hazırlamış olduk. Peki
tabloda arama yapmak istediğimizde nasıl bir yol izlememiz
gerekecek. Şimdi tablomuz üzerinde arama yapacakk fonksiyonumuzu
yazalım.
Bu aşamada hash tablomuzu hazırlamış olduk. Peki
tabloda arama yapmak istediğimizde nasıl bir yol izlememiz
gerekecek. Şimdi tablomuz üzerinde arama yapacakk fonksiyonumuzu
yazalım.
int find_row(char *str)
{
int hash_index;
Row *row;
hash_index = RSHash(str, strlen(str)); //
benzersiz değer hashing fonksiyonu ile yeniden hesaplanır
if (!strcmp(table.rows[hash_index].name,str))//belirtilen
indise bakılır
return table.rows[hash_index].index; //veriler
aynı ise indis ile geri dönülür
else {
row = table.rows[hash_index].pNext;
while(row) //bağlı
liste varsa kayıtlar takip kontrol edilir
{
if(!strcmp(table.rows[hash_index].name,str))
return table.rows[hash_index].index;
// Eğer aranan kayıt bağlı listede ise
row = row->pNext;
// diğer kayda gecilir
}
}
return -1; //bulunamadı
ise -1 ile fonksiyon sonlandırılır
} |
Bu noktada hashing yönteminin ne kadar faydalı
olduğunu görmekteyiz. Aramak istediğimiz değere eğer catışma yoksa tek seferde
erişebilmekteyiz. Öncelikle bulmak istediğimiz veriyi kullanarak yine aynı
hashing fonksiyonu ile bir değer üretiyoruz. Bu değere karşılık tabloda aynı
indisli kaydın değerine bakıyoruz. Kullanılıyor ise verileri karşılaştırıyoruz
uyuşmuyor ise bağlı diziyi kontrol ediyoruz varsa indis değeri ile geri
dönüyoruz yoksa da -1 değeri ile fonksiyonumuzu sonlandırıyoruz.
Uygulamamızda bahsettiğimiz çatışma çözme yöntemleri
temel ve basit çözüm yollarını göstermektedir. Tabiki birçok durumda daha
değişik ve kompleks çözüm yolları gerekecektir. Hasing yönteminin hızı
kullandığımız hashing fonksiyonuna ve çatışma çözmede kullandığımız yollara
bağlı olacaktır. Farketmiş olsak da olmasak da bir çok uygulamada hashing
yöntemi kullanılmaktadır. Pratikde birçoğumuzun kullandığı p2p programlarında
(e-mule, DC++ gibi) bu yöntem sıklıkla kullanılmaktadır. Paylaşılan
dosyanın belirli bir bölümünden benzersiz bir değer üretilerek, aynı dosyanın
ismi değişik olsa dahi aynı dosya olduğunu anlayabiliriz. Aynı zamanda .Net te
çok iyi bir şekilde implemente edilmiştir. string işlemleri için .net te
StringDictionary sınıfını inceleyebilirsiniz.
Mutlu ve sağlıklı günler.
Uygulamanın kaynak kodlarını ve çalıştırılabilir
dosyasını burdan indirebilirsiniz.
Makale:
Hashing Fonksiyonları, Hash Tablosu ve Collision C ve Sistem Programlama Oğuz Yağmur
|
|
|
|
|
-
-
Eklenen Son 10
-
Bu Konuda Geçmiş 10
Bu Konuda Yazılmış Yazılmış 10 Makale Yükleniyor
Son Eklenen 10 Makale Yükleniyor
Bu Konuda Yazılmış Geçmiş Makaleler Yükleniyor
|
|
|